
Field Notes
The AI-Friendly Tech Stack I Like Right Now
Quick Summary
tl;dr: Typed languages are crucially important for AI on big projects. TypeScript is the best typed language for AI. AI is now REALLY good at writing SQL; even in mid-last year it sucked. Easily flowing types from DB->Backend->Frontend is an even bigger win now. Infra, upgrades, testing, and maintenance are easier than ever before.
My current (March 2026) coding setup
I am actively building and maintaining several projects, and I have mostly converged on the same stack for all of them, unless I otherwise inherited them from someone else (Python & Next.js projects lol).
As far as coding agents, I was heavily using GPT-5.3-codex, and now I am using GPT-5.4, both in the Codex harness on the command line mostly, on desktop Linux.
I still use Claude Code in some scenarios, but it’s accurate to say I usually reach for Codex first because it’s better at coding and more… tireless maybe is a good way to describe it. Claude Opus in the Claude Code harness is great at tool calling and has more opinions and taste. I use Claude for UI work and some MCP server work like looking at Posthog and logs.
I am running tasks in parallel (but not a ton), and I’m not using any big multi-agent harnesses like Gastown or Ralph Wiggum or whatever. I think they produce slop and layers of cruft, and I still want to steer big decisions. Many times the models decide to add new code rather than fix or refactor old architecture. They often start fixing symptoms of problems instead of discovering the root of the issue (when presented with e.g. error logs).
How do I actually work with agents and code?
My system is pretty simple: I often generate research documents using GPT-5.x PRO, or deep research, or GPT-5.x extended thinking (OpenAI truly is generous with search capabilities, more so than Anthropic), and then I usually make a spec for my feature by hand where I clearly define goals and outcomes, reference the research documents (e.g. documenting APIs), and then I let the model work from that.
I have the agent maintain a checklist in Markdown. The model does it all inside of its harness and using the reference documents and checklist (I often tell it to record where the files are that it created/changed). It lets me come back to projects between sessions and load in other project context when concerns cut across each other. This system is very simple but gets around context issues, and I think it doesn’t lock me in to any specific tools.
In AGENTS.md I explain basic things and list out where different projects and files are in the monorepo.
Current stack I am using
- TypeScript
- Postgres
- tRPC
- React
- Vite (for testing also)
- Supabase hosting (primarily bc of connection pooling & the convenient UI)
- Lambdas (AWS)
- Cloudflare for static bundle hosting
- CDK for AWS deployments
- GitHub actions for CI/CD
- Everything in one monorepo
- Astro for marketing / SEO-focused websites
Why this stack works well with AI
I really think it comes down to two things:
- AI models are good at working in this stack.
- I can have static types everywhere.
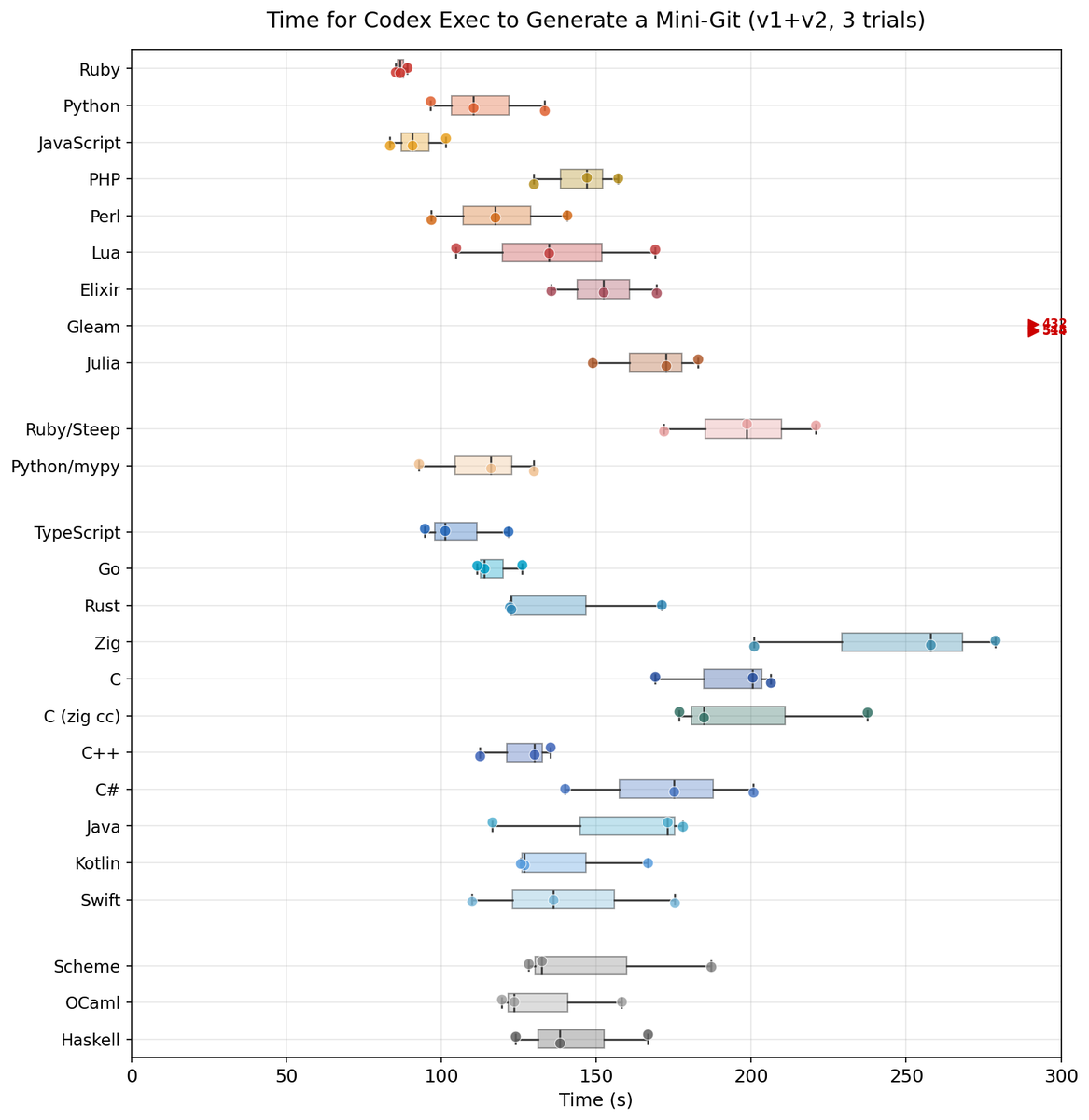
Neither of those should be taken lightly. Firstly, I will point out there is strong evidence that TypeScript is one of the typed languages that current AI models are best at using. You can see evidence of that below.
And the ability for AI to use types to instantly get feedback about correctness is very helpful. Any time you can make a closed loop with an AI agent, you can get incredible things happening, and this is what the type systems help accomplish.
Additionally: the Node.js runtime (which is what TypeScript compiles to) is relatively fast and efficient when compared to languages like Python or Ruby, and of course the benefit of having the native language, and native transport data structure, on the web browser cannot be overstated.
SQL
I saw something funny on Twitter last week; it was to the effect of “MongoDB is dead because AI is good at SQL now, and Mongo only existed because people were too lazy to learn SQL”.
I think, as funny as this is, in my actual experience there is a lot of truth to this statement. Postgres supports JSONB columns very well now, as well as tons of other features, so I’m not sure why you would pick MongoDB for a new project.
The ability of AI models to write good SQL has dramatically improved. In the summer of 2025 they would routinely fail to build complex SQL statements correctly, but now in March of 2026 I am seeing both Claude and GPT-5.3-codex optimize incredibly large, complex SQL queries easily.
Maintenance And Infra
In the past I would put off a lot of maintenance and infra tasks with this exact reasoning:
My time is very limited so instead of struggling to optimize this app I’m just going to upgrade the size of the DB and server and use money to solve the problem.
Another example:
I know this job is very inefficient and it could be refactored to use fewer resources but it’s just not a priority so we will just run it at 2 AM so it doesn’t impact production users.
Or, even better:
Yeah I know I need to upgrade my React version but if I do that I will have to upgrade all of these other dependencies and I can’t read the changelog of everything and test everything so we will just have to make do with what we have until we have time later.
AI agents that code well obviously change the calculus of all of these things.
You can do all of the following things now probably 100x easier than before:
Keep your packages updated to the latest version Fix perf issues as soon as you notice them Refactor old mistakes Simplify infra that would have been extremely laborious to untangle before.
The fact that codex can do this loop:
- Inspect AWS environment using APIs
- Run CDK scripts
- Inspect AWS environment using APIs
Makes so many things so much infinitely easier on the ops side. I don’t think it’s possible to understate this.
Using more exotic languages
I think the calculus will also change about using more exotic languages that have specific performance benefits.
To me right now, Go and Rust are looking nicer than ever before.
Or if I have something that fits the bill why not use WASM?
Adding some more complex tool to the toolchain just got cheaper.
Deferring projects
Another thing I saw people talk about is deferring engineering projects that would be very hard right now out a year or so because the models are expected to improve.
So, to be quite honest, that’s where I was last year on a lot of things, and as soon as GPT-5.3-codex came out and I experienced how good it was, I started to do a TON of old deferred projects.
Maybe in big companies the good models will not trickle down to employees for another year, but I expect pretty soon a lot of projects that were deemed “too hard, not worth it” are going to start getting done.
Supabase
Supabase has become very popular with vibe coders, I believe because it’s embedded in things like Lovable, and you can access it client side without setting up a server.
I will say I really like this about Supabase:
- The interface
- The built-in connection pooler (you need it with lambdas)
The things I don’t like about Supabase:
They do let people shoot themselves in the foot pretty easily…
- No, it’s not good to call the database from the client.
- No, it’s not good to compute row-level security on every query.
- No, the Data API they made is not efficient or easy to reason about when you have performance issues.
- No, you cannot easily solve issues if you can’t even figure out what clients are calling your API and from where with the Anon key.
I think it’s a constant self-induced DDOS risk even if you do set everything up perfectly from a security standpoint.
But the good news is, you don’t have to use the Data API, you don’t have to use the client key, you don’t need to call it client side!
I think there will be a lot of work for a lot of engineers undoing these bad patterns once applications hit production scale.
BTW if your Supabase is crashing constantly or running out of IO Your Supabase Project zzz is running out of Disk IO Budget, I will fix it for you if you pay me.
I’m serious, I spent a lot of time dealing with this already and I am pretty good at tuning Postgres.
Are you getting emails like this?
Your project is depleting its Disk IO Budget. This implies that your project is utilizing more Disk IO than what your compute add-on can effectively manage.
Shoot me a message or book a meeting, you will have to pay me but probably less than you are thinking. I can either diagnose or solve these things in an hour typically, and I don’t even charge as much as your local mechanic (well, if you are in the USA anyway).
March 2026 summary
- Typed languages are king with AI coding
- Postgres is still amazing
- The golden stack of JavaScript everywhere is better than ever
- Supabase vibecoding - remember to call me if you get: Your Supabase Project is running out of Disk IO Budget
- Maintenance is easier than ever
- Maybe we should start taking advantage of more performant languages!