
Field Notes
AI 2030: projections and predictions
 Nanobanana: generate an image of this conversation for AI in 2030
Nanobanana: generate an image of this conversation for AI in 2030
Quick Summary
A bottom-up projection of AI inference revenue through 2030, with a base case of ~$790B in annual spend. The biggest demand buckets are consumer assistants, coding copilots, voice agents, and cybersecurity. Google and OpenAI are projected to each capture ~22% of model revenue, with Anthropic close behind at ~14.5%. Agentic swarms alone could add another $243B in compute demand on top of that. The range of plausible outcomes is wide, but $500B-$1T in annual inference revenue by 2030 is not an unreasonable estimate.
2030 is less than 5 years away, and there has been much debate lately around if AI is in a bubble, if progress is slowing down, or if it will cause mass unemployment and somehow destroy all humans. Despite the silly narratives in both directions it seems that in general progress is still happening at a good pace and there are four major labs now with cutting edge models pushing new capabilities and breaking benchmark high water marks every few months.
As an investor though, I want to try to understand potential token demand sources and who will end up accumulating revenue.
I worked with GPT 5.2 thinking and GPT 5.2 pro a bit to refine these projections.
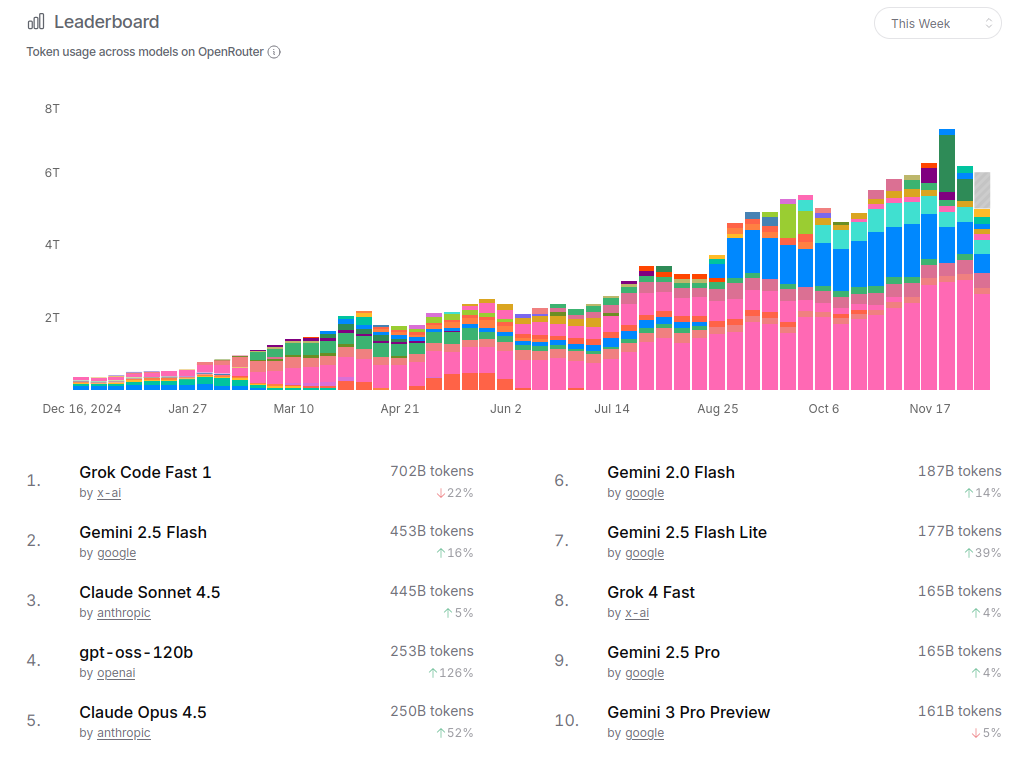
OpenRouter December 2025
I’m writing this in December 2025 and I always like to snapshot OpenRouter just for a kind of vibe check on token usage.
I will say for the remainder of this article xAI isn’t really included much but it’s pretty clear they made grok-fast-4.1 very good and cheap and people are using it for things (including me). How they turn this into a lot of revenue it’s not super clear yet.
Revenue by inference application
First let’s try to bucket each source of inference demand in 2030. It’s safe to assume consumer and enterprise assistants will still use a lot of tokens. But there are a ton of other applications we should think about.
This is annual inference spend run-rate in 2030 (what customers pay for model calls; excludes training). Base case total: $790B.
| workload bucket | 2030 spend (US$B) | what matters for “who wins” |
|---|---|---|
| consumer assistants (chat/search/tutoring) | 180 | distribution + bundling |
| white-collar docs (legal/finance/hr/ops) | 80 | enterprise trust, compliance, integration |
| coding copilots | 70 | workflow lock-in; coding share already concentrated today (OpenRouter) |
| voice agents (call handling, scheduling, sales) | 70 | low latency + TTS/ASR specialists still matter (Poe) |
| cybersecurity & threat detection | 70 | on-prem + auditability + agentic triage |
| robots/cars/industrial autonomy control | 60 | edge inference + safety + real-time |
| customer support agents | 40 | cost curve + reliability |
| video creation | 35 | compute intensity; China already strong in usage on Poe (Poe) |
| video analysis / analytics | 35 | surveillance/retail/industrial adoption |
| observability & log intelligence (app/iot/infra) | 25 | “cheap intelligence” at scale |
| image creation & editing | 25 | model quality jumps cause rapid share flips (Poe) |
| image analysis / vision | 25 | edge + vertical CV stacks |
| healthcare & biology inference | 25 | regulation + validated tooling; FDA is starting to qualify AI tools (Reuters) |
| simulation & digital twins | 20 | engineering + industrial “digital ops”; big market, but inference is a slice (Grand View Research) |
| social media analysis & moderation | 15 | platform + brand safety |
| gaming/VR interactive agents | 15 | latency, local inference, UGC scale; huge gaming TAM but inference slice is smaller (Grand View Research) |
Model company revenue shares
Next, who is going to be capturing this revenue?
| provider bucket | 2030 inference revenue (US$B) | share |
|---|---|---|
| 176.0 | 22.3% | |
| OpenAI | 172.3 | 21.8% |
| Neocloud / open weights (Together/Fireworks/Groq style) | 114.8 | 14.5% |
| Anthropic | 114.5 | 14.5% |
| China providers (ByteDance/Alibaba/etc, incl. video) | 77.0 | 9.7% |
| Other long tail | 60.0 | 7.6% |
| Edge / local OEM (auto, robots, devices) | 39.0 | 4.9% |
| Specialists (media/audio like ElevenLabs/Runway/etc) | 36.5 | 4.6% |
New paradigm inference sources
Next, we try to model out some new paradigms / sources of inference demand that don’t really exist today.
Specifically around the “agentic swarms” idea, I think we can kind of assume that it’s likely there will be a lot of agentic AI type employees that join your slack and then respond to things and do tasks.
In the background these agents should be able to work together to accomplish tasks. I can imagine soon you will have a ton of virtual environment based agents with accounts and stuff controlling computer browsers and doing things end to end. That’s likely where we are going very very soon. I would be super happy to have this to e.g. do various tasks related to accounting or twilio compliance for example. Right now the tools like Manus, or Claude computer use are just not that good yet and they are very slow and make too many mistakes. That probably changes this year.
| paradigm | endpoints/users | events rate | compute per event | effective $/compute | 2030 spend ($B/yr) | cloud compute implied |
|---|---|---|---|---|---|---|
| agentic swarms (enterprise autopilots) | 300M active knowledge workers (subset of ~644M-997M) | 100 agent-steps/user/day | 10 H100-sec/step | $8 per H100-hr (blended) | 243.3 | ~30.4B H100-hr/yr (3.47M always-on eq.) |
| system 2 + verification tax (deep reasoning, proof-carrying output) | 500M deep runs/day (global) | per run | 200 H100-sec/run | $12 per H100-hr (premium) | 121.7 | ~10.1B H100-hr/yr (1.16M always-on) |
| video/world simulation (generative video, interactive worlds, sims) | 2B output-sec/day | per output-sec | 150 H100-sec/output-sec | $3.5 per H100-hr (commodity) | 106.5 | ~30.4B H100-hr/yr (3.47M always-on) |
| always-on digital twins (continuous monitoring + intervention) | 20M always-on twins | continuous | 0.04 H100 per twin 24/7 | $4 per H100-hr | 28.0 | ~7.0B H100-hr/yr (0.80M always-on) |
| ambient perception (cars + smart glasses) | 120M vehicles + 80M glasses paying; plus cloud assist | cloud assist: 60 H100-sec/endpoint/day for 200M endpoints | see left | Edge subs: $15/mo vehicles, $8/mo glasses; Cloud: $8/H100-hr | 39.0 | cloud only: ~1.22B H100-hr/yr (139k always-on); edge compute not counted |
Conclusion
These numbers are obviously just projections and we have no idea what they will eventually turn out to be. But this is what you can potentially come up with if you model starting from today and extrapolate out inference trends.
I don’t think it’s crazy to say you could have somewhere between 500 billion to 1 trillion in annual inference revenue attributable to the major model providers as well as the open source neocloud providers.
People continue to miss that you can train models on any number of data modalities and the applications are hard to even imagine now.
If anything, it’s really entertaining to write the posts and come back later to see how wrong I was.