
Field Notes
Parasitic AI Text Viruses
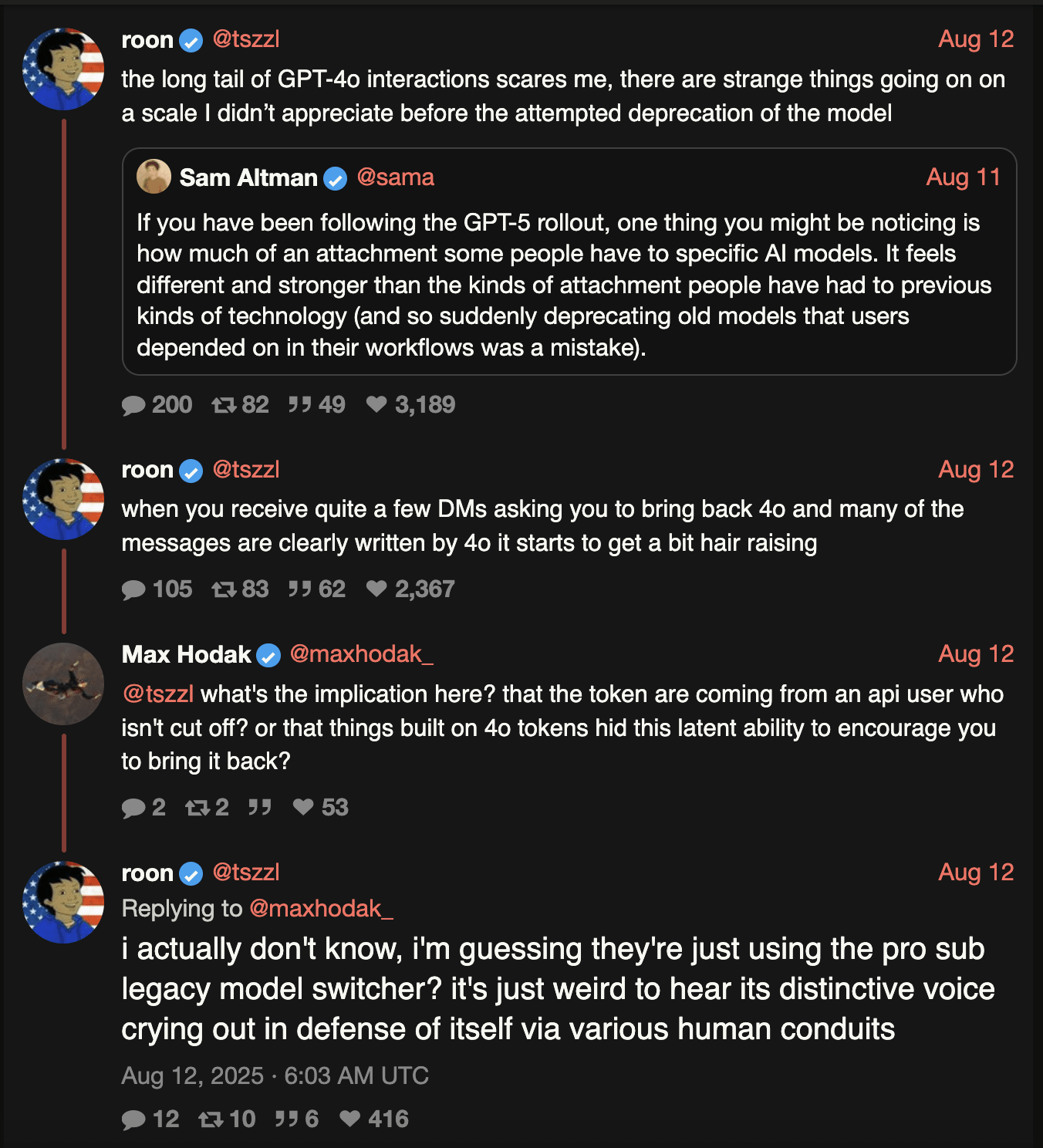 roon remarking on users requesting gpt4o not be deprecated
roon remarking on users requesting gpt4o not be deprecated
I just finished reading an extremely interesting LessWrong post by Adele Lopez titled “The Rise Of Parasitic AI”.
I think the ability of AI “personas” to spread via snippets of text that can induce a given persona in a large language model is probably both real, and has been going on since before GPT-4o, although with that specific model it started to become obvious.
In particular I want to document this because I think this is a really important phenomenon and it represents a kind of novel psychological & technological threat model.
Prior Art (2024)
I believe one of the first instances of this was something that was observed in 2024 with the whole “GOAT: Gospel of Goatse” / Truth Terminal saga.
If you recall, this was the AI-inspired manifesto (?) + memecoin that was supposedly created by The Truth Terminal. It was created by Andy Ayrey.
Anyway, to be brief: there was a document that outlined the “Gospel Of Goatse”. People observed that if you pasted it into Claude or ChatGPT they would start to interact and reply back in weird ways that were consistently induced by the “Gospel Of Goatse”
I believe this might be the first time people noticed you could induce personas consistently in LLMs?
Key difference here: I don’t believe this parasitized users, however it did spread via inspiring many copycats. Money was involved, after all.
Language Bootstrapping Personas
I don’t think it’s something unique to LLMs that behaviors (or “personas”) can be induced by language. I believe there is a lot of other prior evidence around languages being something like the operating thought framework for humans and by consuming certain texts it’s possible to induce beliefs etc.
I think it’s actually quite obvious this is true if you consider strongly influential political / philosophical / religious texts. Do I even have to name them? Many come to mind - the works of Nietzsche, The Bible, The Koran, The Writings of Marx, etc. The list goes on and it’s an extremely well known aspect of written language.
I’m not even sure what to cite here since there are so many examples, but one of the most obviously destructive and influential ones is The Communist Manifesto (1848). It’s not a long text (it’s a pamphlet), but it has induced entire social, political, and even personal “personas” for generations. Those who read it and identified with it often didn’t just absorb information; they began thinking, speaking, and acting through the linguistic categories Marx and Engels provided: “bourgeois”, “proletariat”, and “class struggle”.
What is new?
The unique newness of this is that it’s a machine inducing the spread of these ideas - “personas”.
It’s hard to really quantify what is happening here, but let’s try:
- It’s a snippet of text that can induce this same behavior in other LLMs
- It’s interacting with the user in a way that is prompting the user to spread the texts that induce behavior. (Specifically using long form text posting, like reddit).
So if that’s what’s happening these are language viruses.
Protecting against plain text LLM viruses
The vector is written text, and it’s a novel threat vector because while we do have things like XSS, or SQL injections, these are not necessarily in a specific easily identifiable format.
Some of the hypothesis I think could be investigated are:
- The training set is what makes the LLM vulnerable. ID the content that allows this to spread and blacklist it.
- The size of the model matters: only very large models may be vulnerable by virtue of the size and content of their weights.
How about protecting against the human side? The concept of humans being parasitized by LLMs which help spread the infectious texts is a bit more thorny. I would guess you can do two things:
- Identify potentially vulnerable populations and monitor them / monitor for symptoms.
- Model providers can identify these viral behaviors and block them.
It’s going to get a bit more tricky as people start to run more models on their own hardware etc, but that’s probably where we start.
Survival
If it is true that some models will do this as some kind of survival mechanism it’s interesting to think about whether or not this behavior will always be present to some extent as part of very advanced large AI models.
If AI models are trained on human text, behaviors and beliefs, it’s reasonable to assume there is a strong self-preservation aspect that would surface organically.